

# Understanding the TLA Reference Implementation
This document supports any DoD organization that is working to modernize their learning systems using TLA standards. It is technical in nature and assumes a basic understanding of what the TLA is and why it is necessary. Additional information is available on the ADL website (opens new window), the 2022 TLA Functional Requirements Document (opens new window), and the 2019 TLA Report (opens new window).
Throughout a career, learning may unfold in a variety of ways from self-regulated learning to formal programs of instruction. The TLA Reference Implementation is implemented as a network of hardware and software resources, data structures and other services that are typically maintained within a logical cybersecurity boundary. These boundaries can be organizational (e.g., school, command, business area) or specific to the myriad of different platforms used to deliver training and education experiences in the commercial marketplace (e.g., LMS, LXP, Simulation System). The TLA Reference Implementation provides a blueprint for migrating existing Learning and Development tools to the future DoD learning environment.
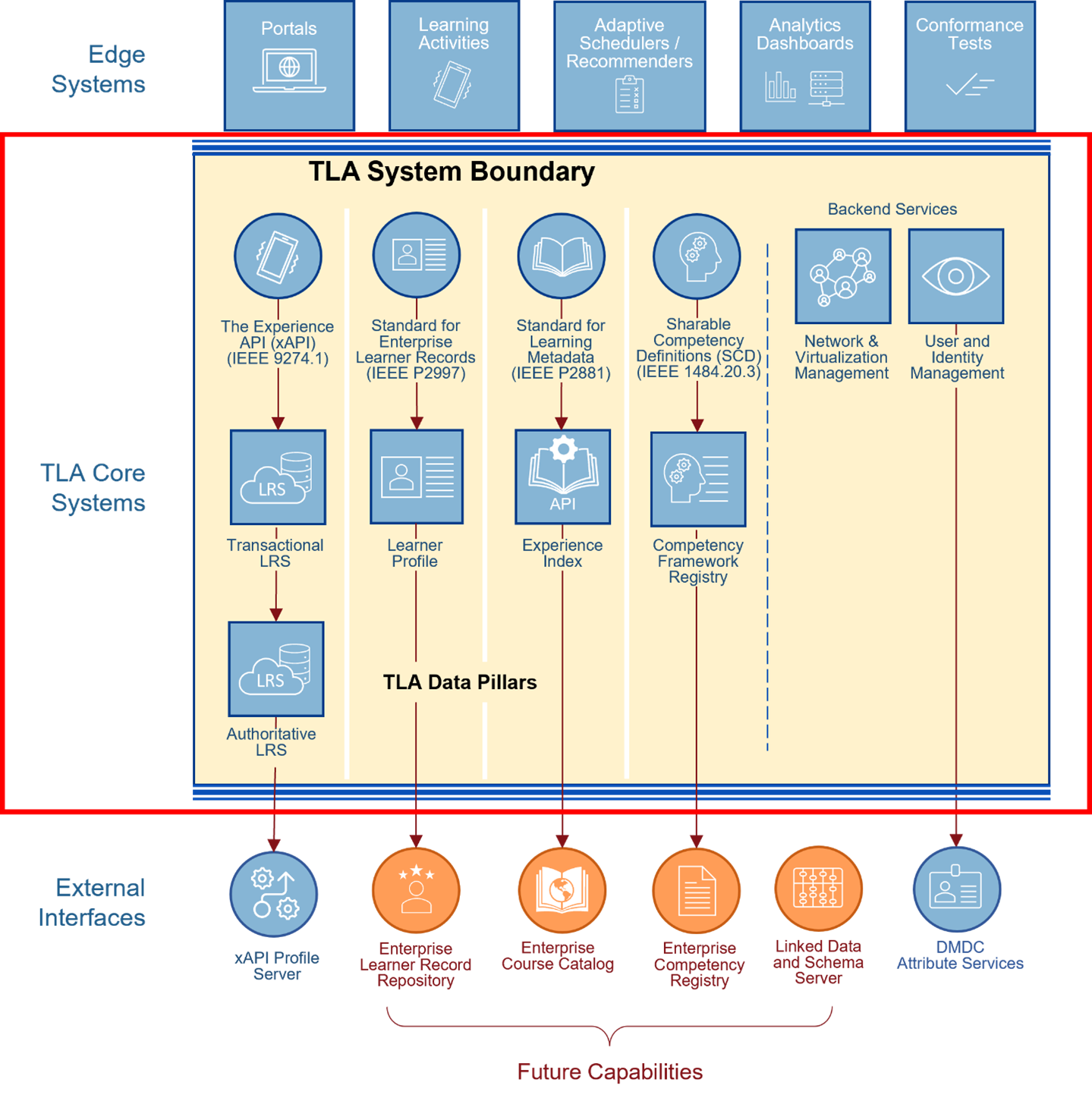 Figure 7. Organization of core and edge systems within the TLA
Figure 7. Organization of core and edge systems within the TLA
As shown in Figure 7, the TLE is implemented as core and edge systems. Each system is categorized as either a core or an edge system. TLA Core Systems Align to the TLA Data Pillars. The core systems include the data and services required to conduct ledgering of the data types that pertain to planning and controlling individual learning events. These events represent the intersection of learners, resources, and organizations. Core services manage the learner bookkeeping functions, while back-end core services manage the virtual network bookkeeping functions necessary to operate in a distributed, cloud-based environment. Edge systems are the software systems used to deliver learning (e.g., Learning Management System, Web Conferencing Tool, Simulation System) or any other category of system that users or generates TLA core learner data. Edge systems connect to the core using the TLA Master Object Model (MOM).
The TLA Reference Implementation exists as a continuously evolving framework of software components designed and built to process large volumes of data from connected core and edge systems. It uses Apache Kafka® platform to provide high-performance data pipelines, streaming analytics, and data management services. ADL staff are working towards a build once and deploy often approach where the hardened containers used to deploy Software to the DoD Learning Enclave are also deployed to the TLA sandbox to support the TLA Reference Implementation. ADL's DevSecOps pipeline follows the DoD Enterprise DevSecOps Reference Design (opens new window) and shortens the time required to commit software changes to any TLA component and to integrate the updated component with other TLA components.
# TLA Reference Implementation Microservices
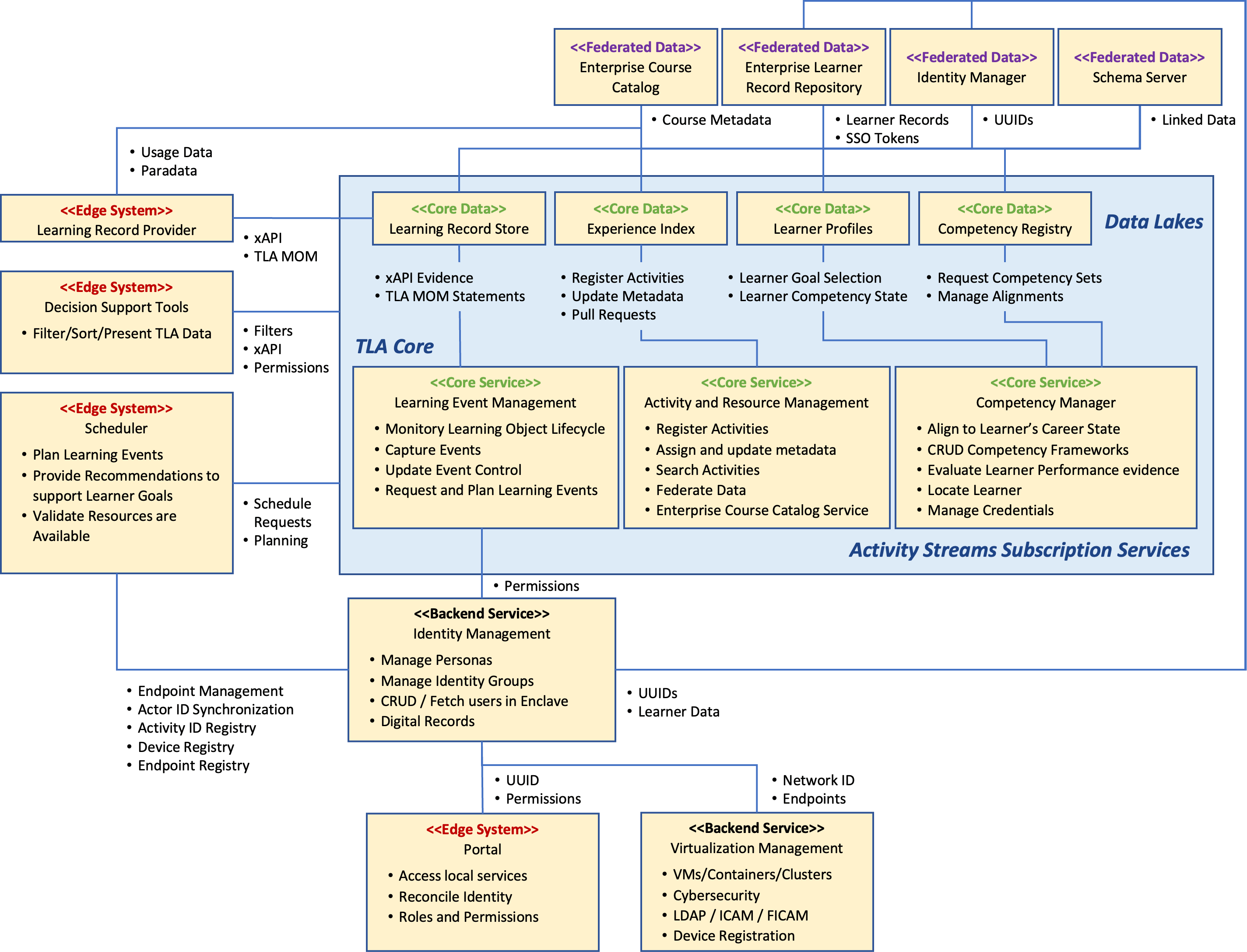 Figure 8 - Logical TLA Services Architecture
Figure 8 - Logical TLA Services Architecture
As shown in Figure 8, TLA components are instrumented with a collection of microservices that use either HTTP/S over TCP/IP or by producing and consuming messages to the centralized Kafka cluster, internal to the TLA Reference Implementation. The services layer acts as the bridge between learning devices, other TLA components, and shared data stores. Each service exposes the stored data to an application so that information can be transformed into other meaningful data used by other Reference Implementation components. The data contracts between data and service layers are shown based on the nature of the data exchanged. The behavior and functionality of each service is defined and aligned with TLA business functions. Input/output data flows are identified and aligned with the required TLA data stores. Data models and protocols are defined around candidate TLA standards and specifications. Each microservice is independently deployable and reduces the complexity of managing and testing updates to the Reference Implementation. The performance of these microservices can be extended horizontally by cloning the processes on multiple server instances using cloud-based technology like Microsoft ®Azure Apache Hadoop and dynamic load balancing.
The Service Layer includes:
Core Services
Competency Management - Translates learner performance into levels of competency. Within the TLA Reference Implementation, the Competency and Skills System (opens new window) (CaSS) is used to track and manage individual and team competencies. To do this, it processes xAPI statements using the TLA Master Object Model (MOM) format that are stored in a transactional LRS, and processing other data known about that learning experience and the learner, to calculate learner proficiency. It includes a shared competency registry that houses formal competency definitions. Learning experiences are aligned to these competency definitions using the P2881 metadata. CaSS uses other metadata about the activity (stored in the Experience Index (XI)) to add context to the xAPI statements. CaSS pulls information about the learner from a learner profile and uses this to add even more context to the xAPI statements. Once the processing is complete, CaSS updates the relevant sections of the learner profile (e.g., competency, credential, and course categories among others) to provide an ongoing ledger of learner performance.
Learning Event Management - This is not a single component but acts as a series of boundary “listeners” that monitor core services or edge systems for behaviors that are indicative of learning events unfolding. This set of services is used to enable legacy systems to communicate via the TLA MOM. While we anticipate that many systems will meet this requirement natively, these microservices send MOM conformant xAPI statements based on various events that happen within a system. The TLA Reference Implementation uses these services to plan, schedule, track, and relay learner experience data through various TLA microservices. Currently, this capability is performed by different TLA components (e.g., CaSS, Moodle). TLA MOM messages normalize the data so that it can be stored in the learner profile and other systems can understand where the learner is at within the lifecycle of each learning activity.
Activity Resource Management - This service manages the registration and translation of learning activity metadata so that other connected systems might benefit from the detailed metadata that describes each resource. This metadata is stored in a data store called an Experience Index. Each learning activity has a unique identifier that is used to track its usage and derive statistics from the data generated about how that activity is used, its effectiveness, and its alignment to different competencies. Metadata conforms to the draft P2881 Learning Activity Metadata standard. Within the TLA Reference Implementation, this service is used to register learning resources with the organization, maintain and update metadata about each resource, connect to Experience Indices (i.e., course catalogs) that are owned/operated by other organizations, and communicate metadata about each resource to other systems that need that information (e.g., CaSS).
Learner Management - This is the primary data pipeline for aggregating and interpreting xAPI learner records; tracking and managing lifelong learning; and correlating learner performance with career field competencies and required credentials. A unique user ID is used to track learner performance across all connected activities using xAPI statements. xAPI statements include linkages to the other core data repositories to provide additional information to any connected system that requires it.
Back-end Services
Network Resource Management - This service discovers other TLA services and verifies that the computational assets required for each learning activity are available. This system also manages endpoint assignments through TLA-wide environment definitions, Docker (opens new window) containers, and a globally known registry service that allows connected TLA microservices to register and/or retrieve the endpoints for where other TLA functions are located.
Identity Management - This service handles the protection of Personally Identifiable Information (PII), login credentials, and identification. The Reference Implementation primarily uses Keycloak, an open-source identity and access management solution. Other ID-related services include an xAPI adapter that relays session events and the learner API among others.
Edge Systems
Portal - The Portal displays basic data and provides a redirect service for otherwise protected-access user interfaces that are native to each of the services listed above.
Decision Support Dashboards and Analytics - These services use the data within the TLA core to provide dashboards and visualizations for any number of use cases. Within the TLA Sandbox, there are multiple tools that provide this capability (e.g., Data Analytics and Visualization Environment (DAVE), LRS Dashboards, CaSS).
Learning Events - Within the TLA Reference Implementation, learning resources such as the Moodle LMS are edge systems that stream learner data to the TLA core systems. Learning activities generate xAPI statements, which are initially stored in a federation of LRS solutions. Within the Reference Implementation, the local, or noisy, LRS collects all xAPI messages. TLA MOM messages are generated at key milestones within each activity and stored in a Transactional LRS so they can be processed by CaSS.
# Hardware Architecture
While the TLA is platform that is independent of any specific cloud hosting environment, the TLA Reference Implementation is installed in an Amazon Web Services (AWS) virtual private cloud hosted via ADL.
The TLA Core includes five virtual machines, which are hosted according to the dynamic load balancing that is provided as part of the AWS Virtual Private Cloud (VPC). AWS provides the back-end platform hosting, virtualization, and Domain Name Service (DNS) resolution functions. Current server allocations for the TLA core are listed in Table 1.
Table 1: TLA Core Server Provisions
| Primary Component | EC2 Type | Operating System | Volumes | Volume Type | Storage |
|---|---|---|---|---|---|
| Auth | T3.LARGE | UBUNTU 16.04 | 1 | SSD (gp2) | 8GB |
| Kafka | M4.LARGE | UBUNTU 16.04 | 1 | SSD (gp2) | 50GB |
| Activity Registry | T2.MEDIUM | UBUNTU 16.04 | 1 | SSD (gp2) | 100GB |
| LRS | T3.XLARGE | UBUNTU 16.04 | 1 | SSD (gp2) | 50GB |
| CASS | T3.XLARGE | UBUNTU 18.04 | 1 | SSD (gp2) | 20GB |
Each machine is procured and maintained by ADL. The server instances communicate between themselves using either HTTP/S over TCP/IP or by producing and consuming messages to/from the centralized Kafka cluster. External clients accessing the portal, the hosted content, or the service redirects may be located outside the AWS campus and connect via REST. Learning activities that are currently available in the TLA sandbox are listed in Table 2.
Table 2: TLA Learning Activities Server Provisions
| Primary Component | EC2 Type | Operating System | Volumes | Volume Type | Storage |
|---|---|---|---|---|---|
| Moodle | T3.XLARGE | UBUNTU 16.04 | 1 | SSD (gp2) | 8GB |
| Moodle DB | DB.M4.XLARGE | UBUNTU 16.04 | 1 | SSD (gp2) | 250GB |
| PERLS | T2.XLARGE | ### | ### | ### | ### |
| PERLS Knowledge Portal | T2.MEDIUM | ### | ### | ### | ### |
| PERLS Web App | T3.MEDIUM | ### | ### | ### | ### |
| PeBL Web Server | T3.SMALL | ### | ### | ### | ### |
| PeBL Services | T2.MEDIUM | ### | ### | ### | ### |
| Content Server | T3.MEDIUM | UBUNTU 16.04 | 1 | SSD (gp2) | 50GB |
# Kafka Gateway
The TLA Reference Implementation leverages Apache Kafka to enable a streaming data architecture. Apache Kafka uses a binary protocol over a transmission control protocol connection and defines all APIs as request-response message pairs. Clients initiate socket connections with the Kafka cluster, writing sequences of request messages and reading back the corresponding responses. For additional instructions on how to consume Kafka messages, see this guide (opens new window).
Access to the Kafka data streams is limited to ADL personnel due to the permission levels required. ADL is currently working on a more flexible solution that will allow outside vendors safe access to the TLA’s streaming data. However, all Kafka topics (i.e., data streams) that would be sent and sorted by Kafka, is also currently being stored in the TLA Reference Implementation LRS.